
引擎解析流程
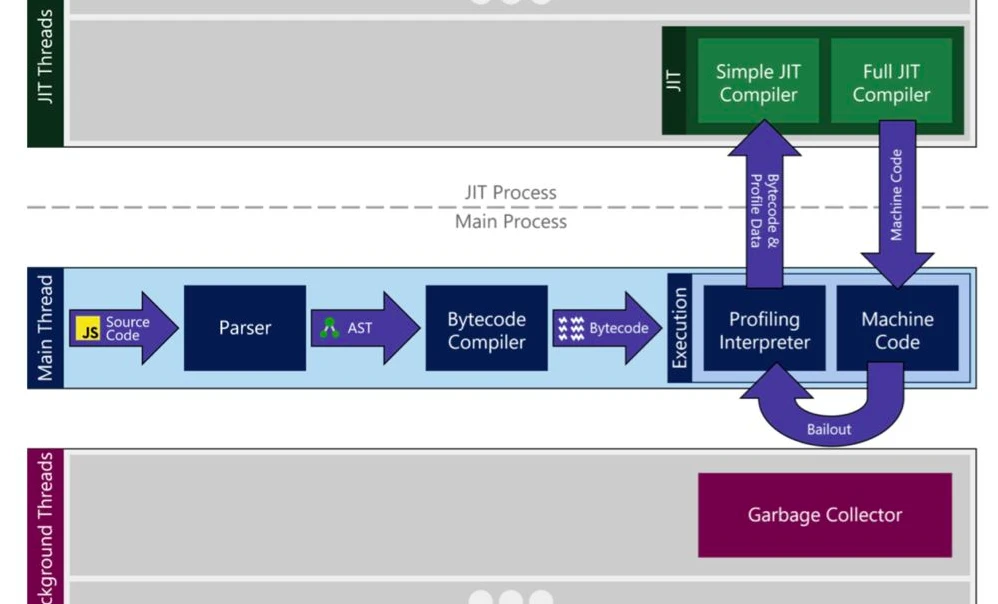
这是 Microsoft Edge 浏览器的 JavaScript 引擎 ChakraCore 的结构。我们来看一看我们的 JavaScript 代码在引擎中会经历什么。
- JavaScript 文件会被下载下来。
- 然后进入 Parser,Parser 会把代码转化成 AST(抽象语法树)。
- 然后根据抽象语法树,Bytecode Compiler 字节码编译器会生成引擎能够直接阅读、执行的字节码。
- 字节码进入翻译器,将字节码一行一行的翻译成效率十分高的 Machine Code。
在项目运行的过程中,引擎会对执行次数较多的 function 记性优化,引擎将其代码编译成 Machine Code 后打包送到顶部的 Just-In-Time(JIT) Compiler,下次再执行这个 function,就会直接执行编译好的 Machine Code。但是由于 JavaScript 的动态变量,上一秒可能是 Array,下一秒就变成了 Object。那么上一次引擎所做的优化,就失去了作用,此时又要再一次进行优化。
window.loaction VS history.pushState
window.location
history.pushState(state, unused, url: optional)
相同点
修改hash都会产生历史记录
pushState优势
- 新的url可以是与当前url相同源的任何url,`window.location`只有修改hash时才会保持在相同的文档中 - 修改url是可选的(optional), `window.location = '#foo'` 如果hash不是 ‘#foo’ 则会产生一条历史记录 -pushState永远不会触发hashChange事件,即使新的URL与旧的URL仅仅是hash不同; import/export、require/modules.exports
// 疑问
import { a } from 'module'
import module from 'module'
const { a } = module;
不同点,为什么import上不可以使用解构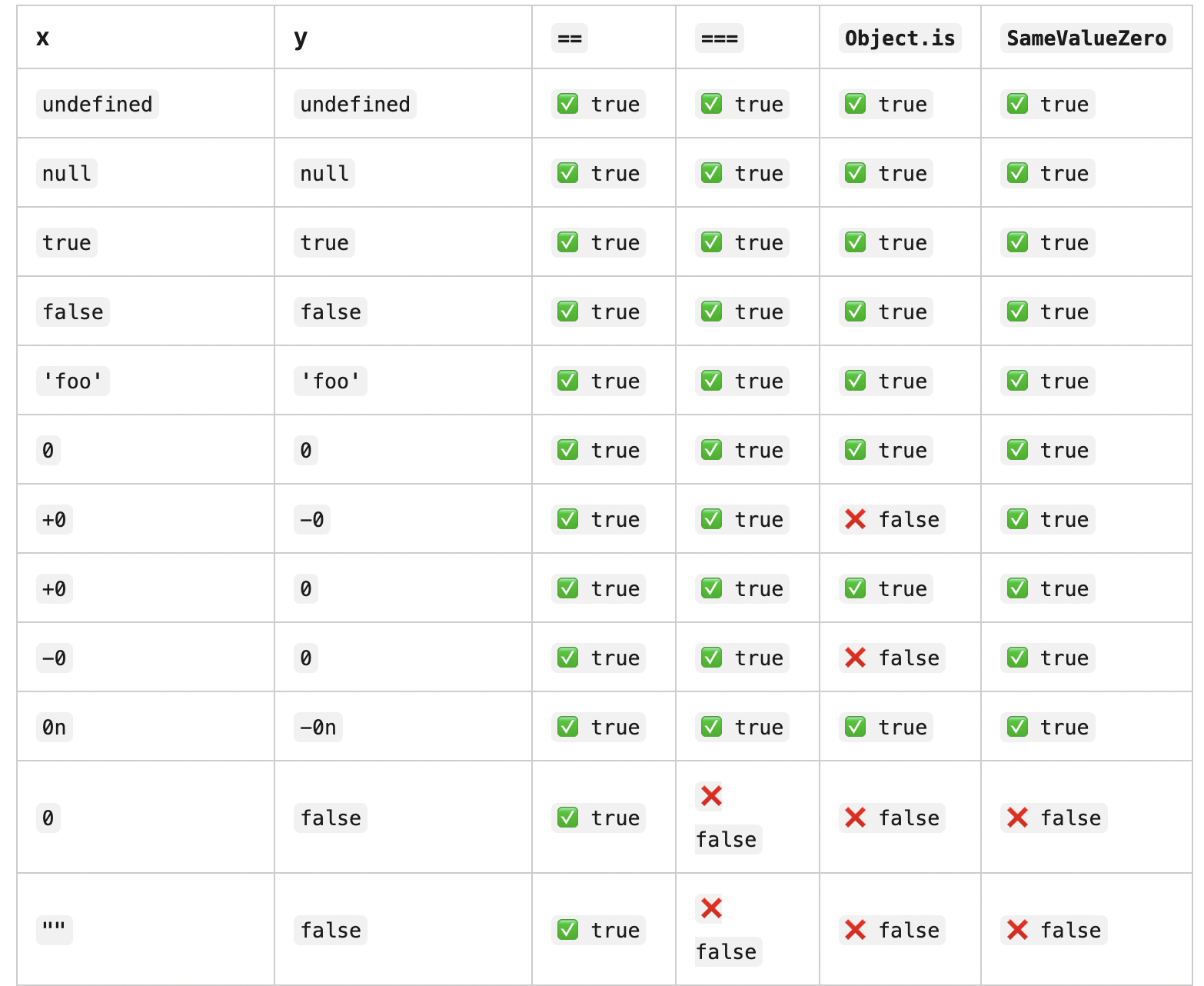
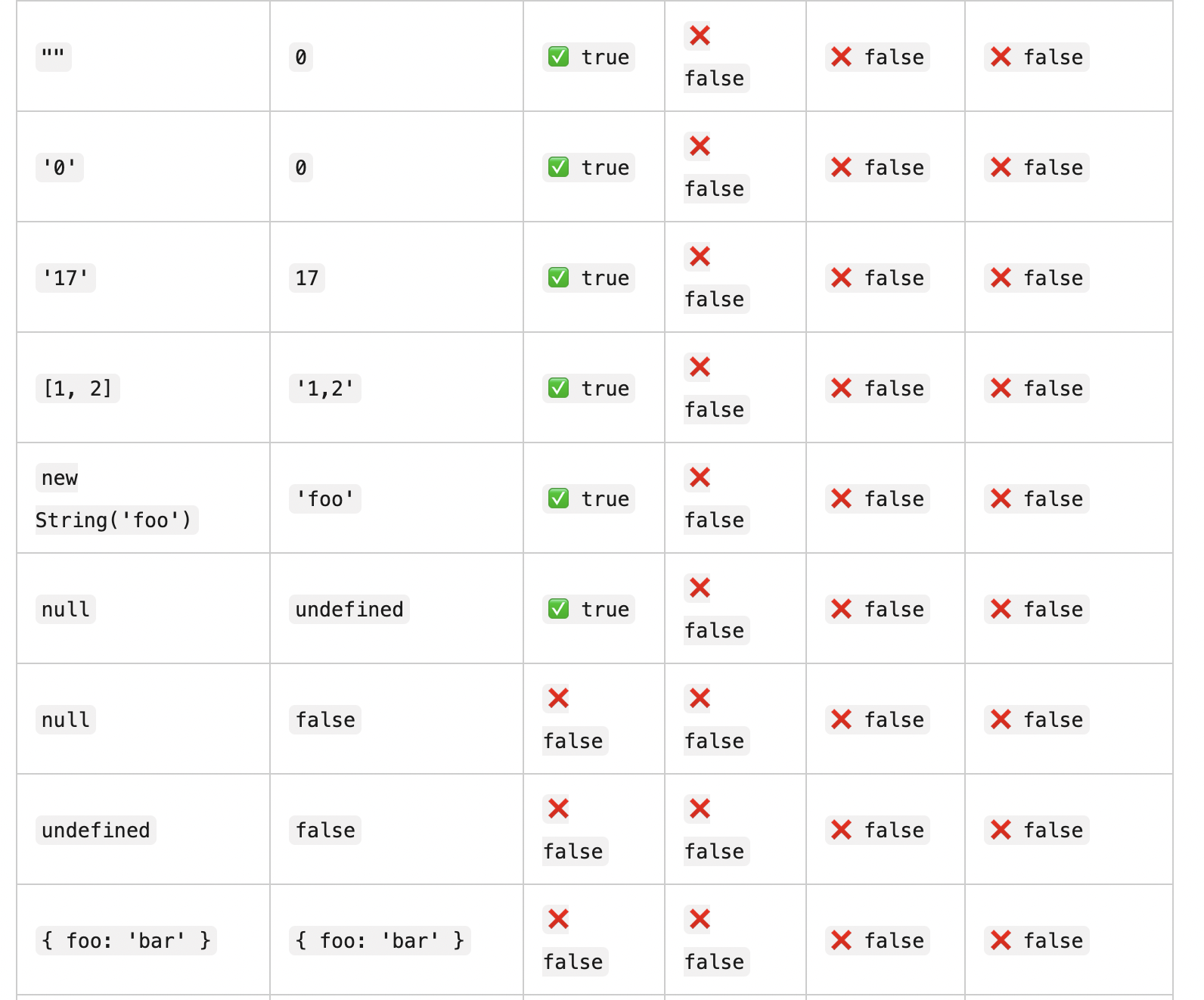
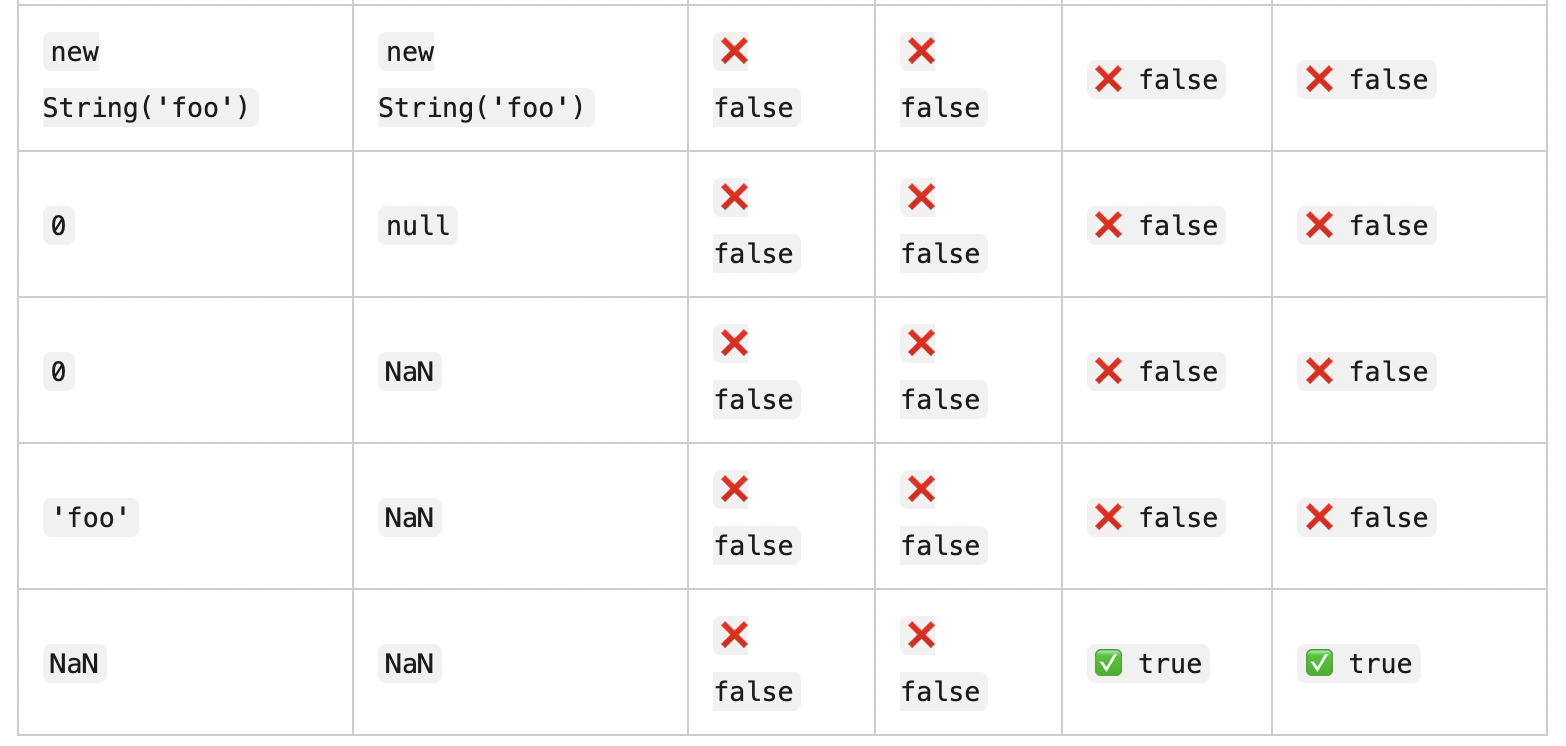
简单来说,typeof null的结果为Object的原因是一个bug。在 javascript 的最初版本中,使用的 32位系统,js为了性能优化,使用低位来存储变量的类型信息。
| 数据类型 | 机器码标识 |
|---|---|
| 对象(Object) | 000 |
| 整数 | 1 |
| 浮点数 | 010 |
| 字符串 | 100 |
| 布尔 | 110 |
undefined | -2^31(即全为1) |
null | 全为0 |
在判断数据类型时,是根据机器码低位标识来判断的,而null的机器码标识为全0,而对象的机器码低位标识为000。所以typeof null的结果被误判为Object。
作者:六寸光阴丶
链接:https://www.jianshu.com/p/68c69bd329ee
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
事件冒泡&事件捕获
事件的流向有三个阶段:捕获阶段,目标阶段,冒泡阶段。
addEventListener函数用于事件绑定,他有三个参数↓
- eventType 事件类型("click之类的")
- function 触发事件后所需要执行的函数
- bool 入参true/false,决定事件在冒泡阶段执行还是捕获阶段执行。 true表示事件在捕获阶段执行,false表示事件在冒泡阶段执行。默认值是false。
blur事件优先级大于click事件
我们知道JavaScript属于解释型语言,JavaScript的执行分为:解释和执行两个阶段,这两个阶段所做的事并不一样:
解释阶段:
- 词法分析
- 语法分析
- 作用域规则确定
执行阶段:
- 创建执行上下文
- 执行函数代码
- 垃圾回收